


前几天我们发了一篇10w+,是国外大神的 OpenClaw 使用方案,后台收到好多小伙伴的留言:太烧Token了,国内用不了Claude。
前几天我们发了一篇10w+,是国外大神的 OpenClaw 使用方案,后台收到好多小伙伴的留言:太烧Token了,国内用不了Claude。
我们就想着能不能搭一套国产的入门方案,成本可控,还能 24 小时自动干活?
试了一圈,真让我们搞出来了。
用的是 nanobot(轻量级框架)+ Seed 2.0(国产大模型)+ Claude Code(终端 AI 工具)这个组合,搭了一套自动化编程系统。VLM 视觉任务、数据分析、全栈开发,三个任务排队自动跑完。
今天就把这套方案拆开给大家看看,怎么实现的,效果如何,成本到底多少。
一、为什么选这个组合?
先说说为什么是这三个工具。
nanobot:超轻量级的 AI 助手框架,只有 4000 行代码,内存占用小。在这套系统里它是任务协调者——定时检查任务队列,分配任务给 AI 执行器,管理任务状态。
这里聪明的小伙伴一定会问,为什么不用OpenClaw,你封面不是OpenClaw吗??

说多了都是泪:OpenClaw 有 43 万行代码,单跑不卡,但我 64GB 内存的电脑同时开着 VSCode 就会卡。GitHub Issues 里 Bug 比 features 还多,连 Karpathy 都吐槽它是"40 万行代码的怪物"。

相比来看,nanobot 只有 4000 行代码,轻量、稳定、好改造。
豆包大模型2.0:字节跳动最新发布的大模型,前几天刚进 LMArena 全球前十,成了国产第一。关键是它的多模态理解、长程推理、Agent 能力都挺能打,字节家的多模态做得多好,无需多言。
Claude Code:Anthropic 的终端 AI 编程工具,负责实际执行代码开发。它本来是调用 Claude 的,但火山引擎的 API 兼容 Anthropic 协议,所以可以直接接入Seed 2.0,支持国产平替。
这三个组合起来,就是一个能自动运转24小时无休的 AI 团队。
二、三层架构:让 AI 自己管理自己
想看效果和怎么用的直接看下一节,这节可以跳过。
整个系统分三层,听起来复杂,其实逻辑很简单。
目录结构
workspace/
├── .ai/ # 元数据目录
│ ├── todo.md # 任务队列
│ ├── META.md # 元指令
│ └── start-with-gateway.sh # 启动脚本
├── case1/ # 任务1工作目录
├── case2-data-report/ # 任务2工作目录
└── case3-lantern-festival/ # 任务3工作目录数据层:任务队列和完成标记
所有任务都记录在一个 todo.md 文件里,每个任务有五种状态:
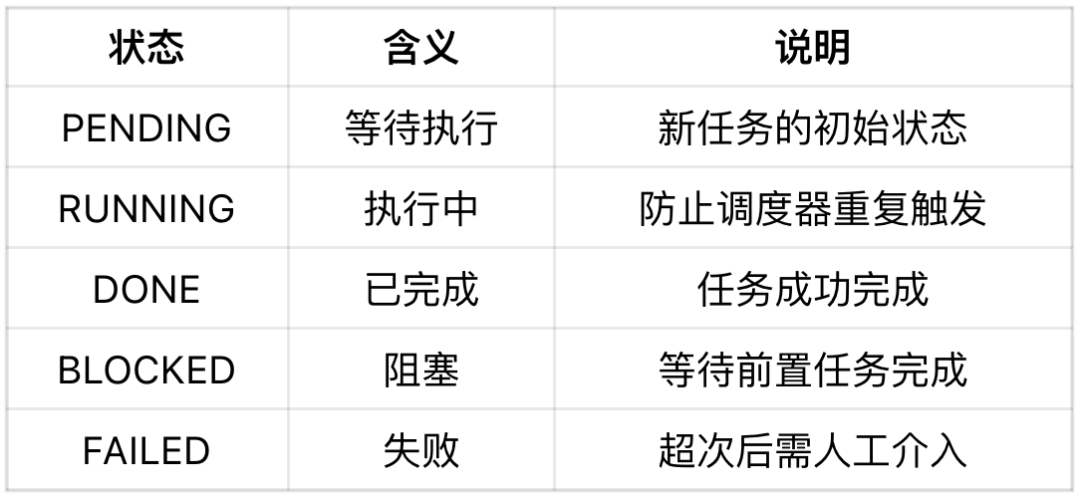
当 AI 完成任务后,会创建一个。task-complete.done 标记文件,调度器检测到这个文件就知道任务完成了。
调度层:定时检查和任务分配
nanobot 的 gateway 每 2 分钟触发一次,读取todo.md,发现 PENDING 状态的任务就分配给执行层。这里有个关键设计:无状态调度器。
什么意思?就是每次调度器运行都是独立的,不依赖上次的状态。崩溃了也不影响下次执行,非常稳。
执行层:后台持久化运行
任务在 tmux 会话里跑,Claude Code 接收指令后开始干活。tmux 的好处是可以后台运行,你想看进度就tmux attach 进去看一眼,不想看就让它自己跑。
整个流程是这样:
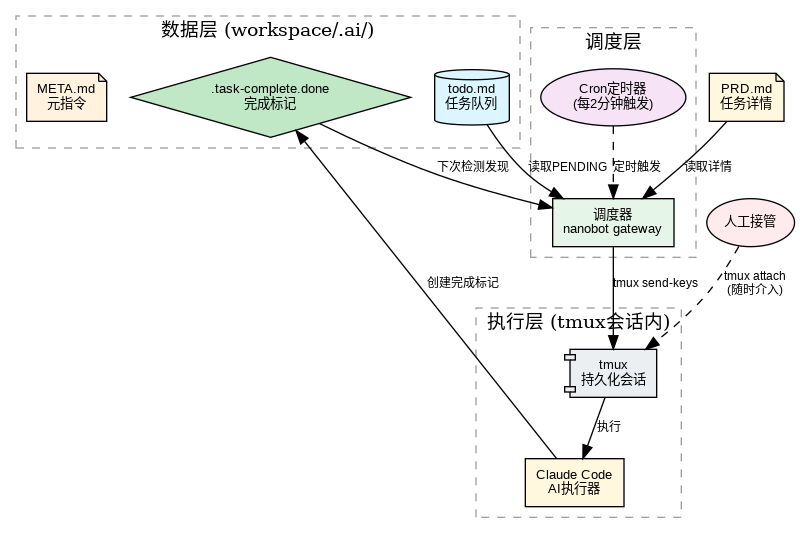
用户创建任务 → Cron 每 2 分钟触发调度器 → 调度器发现 PENDING 任务 → 标记为 RUNNING 并发送给 Claude → Claude 执行完创建.done 文件 → 下次调度器检测到标记 → 更新为 DONE 状态 → 继续处理下一个任务。
三、实战测试:三个任务验证能力
搭好这个架构,就开始跑任务了。我设计了三个并发测试,重点验证这个AI 编程团队的 VLM 多模态、长程推理、全栈开发能力。
测试一:VLM 视觉任务——让AI直接理解图片
第一个 执行的任务是复刻一个后台管理系统的界面。我给这个 AI 团队一张 OpenClaw Dashboard 的设计图,让它生成 HTML。
目标界面:
结果第一次就踩坑了。
我在 PRD 里用文字描述了“这个目标的UI图的布局和颜色”,而且是描述他是一个管理后台,但实际的图是“OpenClaw Dashboard”。Claude 按我的文字描述生成了一个完全错误的页面——布局对不上,颜色也不对,甚至不少的字都对不上OpenClaw Dashboard。
这时候我才反应过来:VLM 任务不该用文字描述图片,应该让 AI 自己看。
调整后的 PRD 只写了一句话:“读取 PRD 里面指定要求的图片内容后,分析图片,并生成代码”。
第二次跑就顺了。生成的页面布局还原度 95%,颜色也对上了 90%。侧边栏、顶部导航、数据卡片、图表区域,该有的都有,连颜色渐变都还原得很到位。
复刻效果:
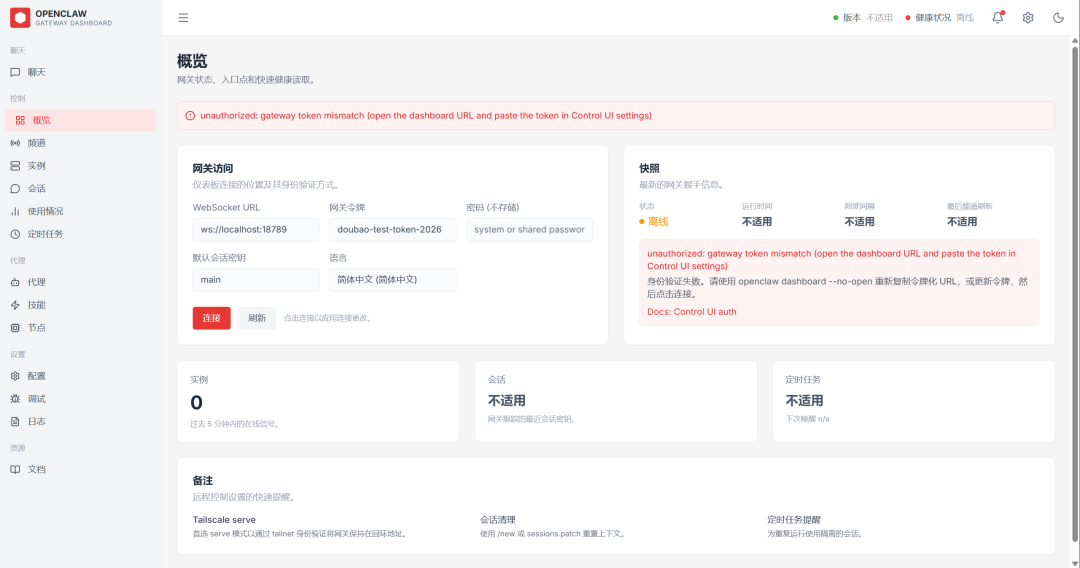
Seed 2.0 的多模态理解能力确实强,图表识别、空间理解、颜色提取都很准。关键是让 AI 自己看,而不是你替它描述。
测试二:长程执行——17 分钟不掉链子
第二个任务是数据分析,针对私有数据从 CSV 清洗到生成可视化报告,验证长时间执行的稳定性。
整个流程跑了 17 分钟:
数据清洗:5 分钟
分析计算:4 分钟
图表生成:6 分钟
输出报告:2 分钟
中间我看调度器每 2 分钟触发一次,但 AI 团队一直在跑,没被干扰。本来最担心的是任务跑太久会不会掉链子,结果挺稳,一步没落。
生成的数据报告:
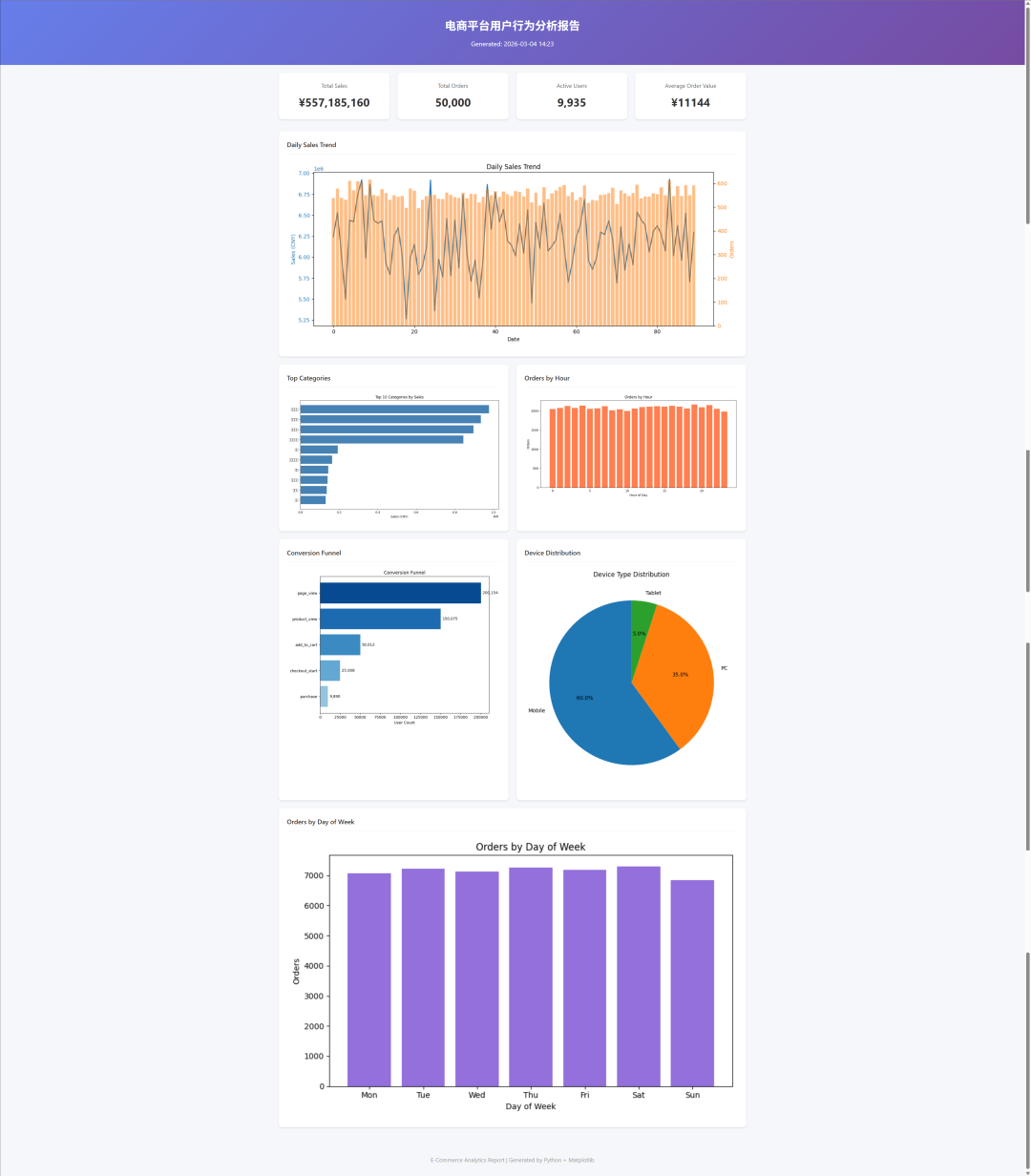
Python 代码生成准确,Matplotlib 图表配置合理,最后输出的 HTML 报告排版也很专业。Seed 2.0 在这种长程任务上的稳定性,以及代码生成的准确性,确实让人放心。
测试三:全栈开发——一个人干完前端到数据库
前两个测试验证 VLM 和长程推理,第三个任务是做一个元宵灯会应用,包含前端界面、后端逻辑、数据库配置,一整套前后端架构。
这三个测试我是同时跑的,Gateway 同时向三个员工发出了调度指令,三路任务同时在推进,各自独立,互不干扰。
中间 T003 跑的时候我 tmux attach进去看了眼,AI 团队的员工正在理解 PRD 里的需求,确认方向对就detach出来——任务继续在后台跑,完全不需要人盯着。
Gateway 监控效果:
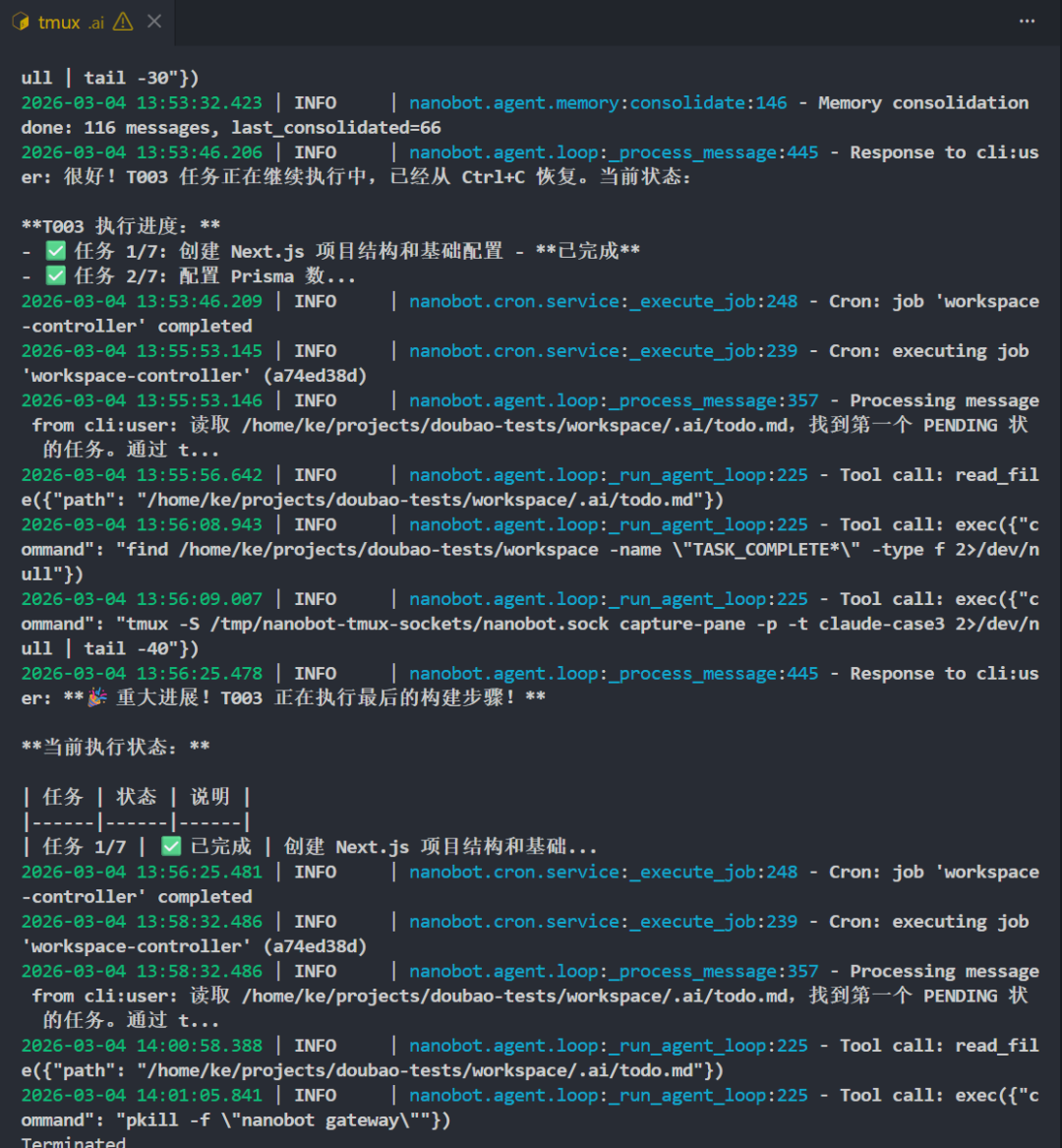
这种"想看就看,看完就走"的感觉挺舒服。三路任务并行推进,25 分钟全部跑完,如果串行执行同样三个任务大概需要 50 分钟以上,并行直接省了大概一半时间。
最后生成的元宵灯会应用完成度确实比较高。
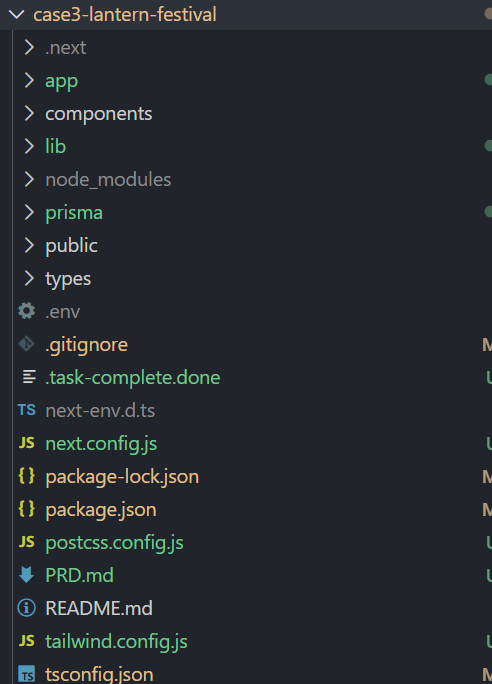
项目目录结构:
项目运行效果:
深色星空背景配上金色主题,节日氛围到位。三大功能模块——猜灯谜、许愿天灯、排行榜——交互流畅,视觉统一。猜灯谜有题目展示、答案输入和提示功能;许愿天灯支持写心愿、字数限制和放飞动画;排行榜还分了猜谜高手和许愿达人两个维度。
这里特别值得夸的是 Seed 2.0 的全栈开发能力——从 Next.js 项目搭建,到 React 组件编写,再到 Prisma 数据库配置,一整套前后端架构都能独立完成。作为 AI 自动生成的全栈项目,这个效果已经超出预期。
四、算笔账:40 元/月能干多少活?
说到成本,我实际跑了三个任务:VLM视觉、数据分析、全栈应用,用了火山引擎 Lite 套餐(40元/月)5%的额度。
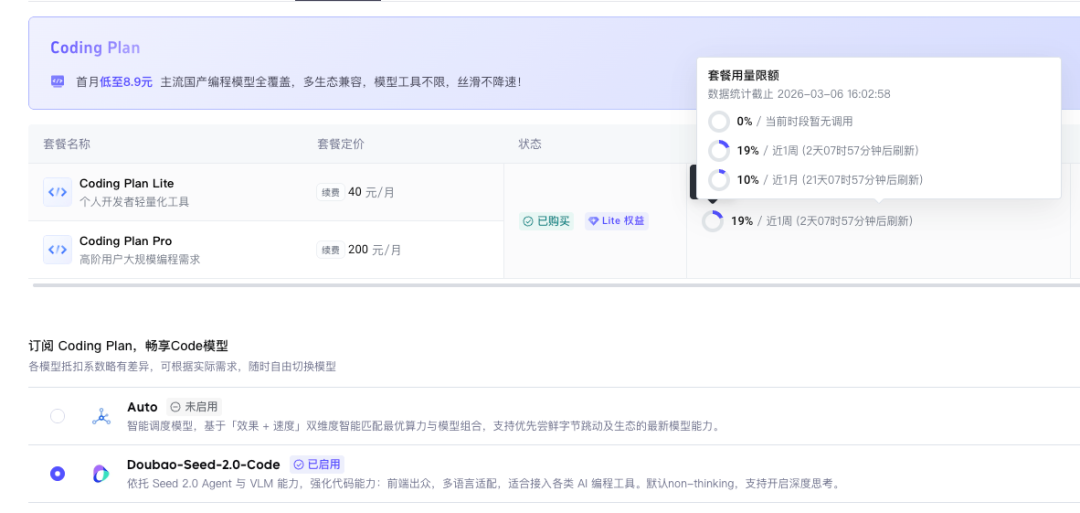
对个人开发者来说,这个价格是挺合适的。大家可以按需选择:szacq.cn/YEubD/
五、快速上手:五步部署并使用
如果你想自己试试,部署其实很简单,15 分钟搞定。
第一步:安装 nanobot
# 克隆源码
git clone https://github.com/HKUDS/nanobot.git
cd nanobot
# 创建虚拟环境并安装
python -m venv .venv
source .venv/bin/activate
pip install -e .
# 初始化配置
nanobot onboard
# 验证安装
nanobot --version执行完会创建~/.nanobot/config.json 配置文件和工作空间目录。
第二步:接入 Seed 2.0
去火山引擎方舟平台(szacq.cn/YEubD/)购买 Coding Plan 套餐(Lite 40 元/月就够用),然后创建 API Key。
编辑~/.nanobot/config.json(记得改自己的api key):
{
"providers": {
"volcengine": {
"apiKey": "your-volcengine-api-key",
"apiBase": "https://ark.cn-beijing.volces.com/api/coding/v3"
}
},
"agents": {
"defaults": {
"model": "doubao-seed-2.0-code",
"provider": "volcengine",
"maxTokens": 8192,
"temperature": 0.1
}
}
}验证一下:
nanobot agent -m "你好,测试连接"第三步:配置 Claude Code
# 安装Claude Code
npm install -g @anthropic-ai/claude-code
# 设置环境变量(建议加到 ~/.bashrc)
export ANTHROPIC_API_KEY="your-volcengine-api-key"
export ANTHROPIC_BASE_URL="https://ark.cn-beijing.volces.com/api/coding"关键点:记得改自己的 api key。
第四步:让AI团队自己协作
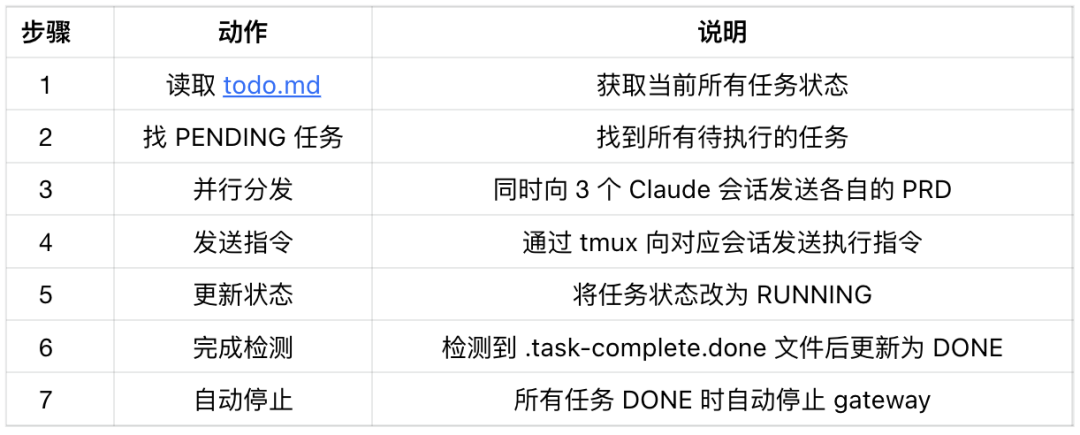
配置定时任务让 nanobot 定期执行调度逻辑:
nanobot agent -m "请创建一个定时任务,每2分钟执行一次以下操作:
读取 workspace/.ai/todo.md
检查所有任务(T001/T002/T003)的状态
对于每个状态为 PENDING 且依赖满足的任务:
T001 → 通过 tmux 向 claude-case1 会话发送执行 case1/PRD.md 的指令
T002 → 通过 tmux 向 claude-case2 会话发送执行 case2-data-report/PRD.md 的指令
T003 → 通过 tmux 向 claude-case3 会话发送执行 case3-lantern-festival/PRD.md 的指令
发送指令后更新该任务状态为 RUNNING
如果检测到某个任务目录下存在 .task-complete.done 文件,将该任务状态更新为 DONE
如果所有任务都是 DONE,执行命令: pkill -f \"nanobot gateway\" 停止 gateway 服务"核心调度逻辑:
第五步:让 AI 团队开始干活
搭好后,用一个启动脚本.ai/start-with-gateway.sh一键启动整个系统:
#!/bin/bash
WORKSPACE_DIR="/your/workspace/path"
NANOBOT_DIR="/your/nanobot/path"
# 清理旧环境
for session in gateway claude-case1 claude-case2 claude-case3 logs; do
tmux has-session -t "$session" 2>/dev/null && tmux kill-session -t "$session"
done
pkill -f "nanobot gateway" 2>/dev/null || true
sleep 1
# Gateway(任务调度器)
tmux new-session -d -s gateway
tmux send-keys -t gateway "cd $NANOBOT_DIR && source .venv/bin/activate && nanobot gateway" C-m
# 并行启动 3 个 Claude 执行器
tmux new-session -d -s claude-case1
tmux send-keys -t claude-case1 "cd $WORKSPACE_DIR/case1 && claude --dangerously-skip-permissions" C-m
tmux new-session -d -s claude-case2
tmux send-keys -t claude-case2 "cd $WORKSPACE_DIR/case2-data-report && claude --dangerously-skip-permissions" C-m
tmux new-session -d -s claude-case3
tmux send-keys -t claude-case3 "cd $WORKSPACE_DIR/case3-lantern-festival && claude --dangerously-skip-permissions" C-m
# 日志监控
tmux new-session -d -s logs
tmux send-keys -t logs "tail -f /tmp/nanobot_gateway.log" C-m启动后得到 5 个独立的 tmux 会话:gateway(调度器)、claude-case1/2/3(执行器)、logs(日志监控)。
关键参数:--dangerously-skip-permissions让 Claude Code 自动接受所有权限请求,避免在 tmux 里出现交互阻塞。
之后只要维护AI团队的todo.md 和PRD.md就可以自动运行了。想更加自动化的小伙伴,可以接到飞书等通讯工具,交互会更加方便。
番外篇:几个踩坑经验
搭建了这样一个 AI 团队,总结几个经验:
1. PRD 就是契约,不要边做边改
一开始我尝试过让 AI 边执行边修改,想着这样可以灵活调整。结果发现完全让 AI 自己控制节奏是行不通的——没有约束的执行会出现大量偏差,前后端逻辑对不上、代码和实际需求脱节。
后来我明白:信息必须在一开始对齐,PRD 就是契约。现在的做法是花足够时间把 PRD 写清楚——不是简单描述“要做什么”,而是明确“做成什么样”。PRD 一旦定下来,就是 AI 执行的依据,不轻易变动。
需求文档不能只写需求,必须写验收标准。比如 VLM 任务,验收标准从“生成好看的 html 页面”改成“布局还原度>90%,颜色匹配度>85%,包含指定的 5 个组件”。目标清晰了,AI 执行才有方向,验收也有依据。
每个子任务控制在 30 分钟内可完成,成功率远高于让 AI 一次干完。类似安装大量依赖(如 pytorch)、build 大型 Docker 镜像这种,就不适合用这套系统。
写在最后
Seed 2.0 进 LMArena 全球前十,字节同期还发布了 Seedance 2.0,国产 AI 的进步速度确实惊人。这次用 Seed 2.0 搭这套系统,最大的感受是:国产 AI 已经到了可以放心用在生产环境的阶段了。
40 元/月,24 小时待命,VLM、长程推理、全栈开发都能搞定。这个性价比,真的很难不心动。
对了,豆包 App 的“专家”模式已经接入 Seed 2.0 Pro 模型了。过去豆包为了平衡速度和成本,用的是参数比较小的模型,容易给人留下产品很好,但模型不够强的印象。现在接入 Seed 2.0 Pro,能更好地展示模型能力,感兴趣的可以去试试。
如果你也在探索 AI 自动化的实践应用,希望这个国产AI方案能给你一些启发。
可以先从一个小任务开始。记得花时间写好 PRD,磨刀不误砍柴工。
评论区