


💡 写在前面
你是不是也遇到过:想在本地跑个大模型,结果环境配置折腾半天,CUDA 版本不匹配、编译失败、依赖冲突……一堆问题?
别急,Llama.cpp 最新版 B9222 直接给你准备好了 Windows 免配置全家桶,解压就能用!不管你是 N 卡、A 卡、Intel 还是纯 CPU,统统搞定。
适合人群:想在 Windows 本地跑 AI 大模型的折腾党、不想折腾环境配置的懒人
预计耗时:10 分钟(下载模型可能需要额外时间)
🎯 一、Llama.cpp 是什么?
简单说,Llama.cpp 就是目前 GitHub 上最火的本地 GGUF 模型推理框架。
你平时听到的那些开源大模型——阿里的 Qwen(通义千问)、Google 的 Gemma 4、还有最近杀疯了的 DeepSeek,全都能通过 Llama.cpp 在本地跑起来。而且 GGUF 生态越来越成熟,社区发布新模型后第一时间就会出量化版本,对内存和显存都很友好。

说白了,有了 Llama.cpp + GGUF 模型,你的电脑就变成了一个本地 AI 服务器,完全不需要联网,数据不出家门。
📦 二、下载全家桶,选对版本
🔹 下载地址:
- GitHub 官方:https://github.com/ggml-org/llama.cpp/releases/tag/b9222
- 夸克网盘:https://pan.quark.cn/s/78bfcef9ddca
🔹 根据你的电脑配置选版本:
| 用户类型 | 推荐版本 |
|---|---|
| N 卡用户(双显卡/独显) | CUDA 版本 |
| AMD 显卡用户 | ROCm 或 HIP 版本 |
| Intel 显卡用户 | SYCL 版本 |
| 纯 CPU 电脑(无显卡) | 常规 x64 64位版本 |
🔹 怎么看自己该选哪个版本?
如果你是 N 卡用户,按下 Win + R,输入 cmd 回车,然后执行:
nvidia-smi
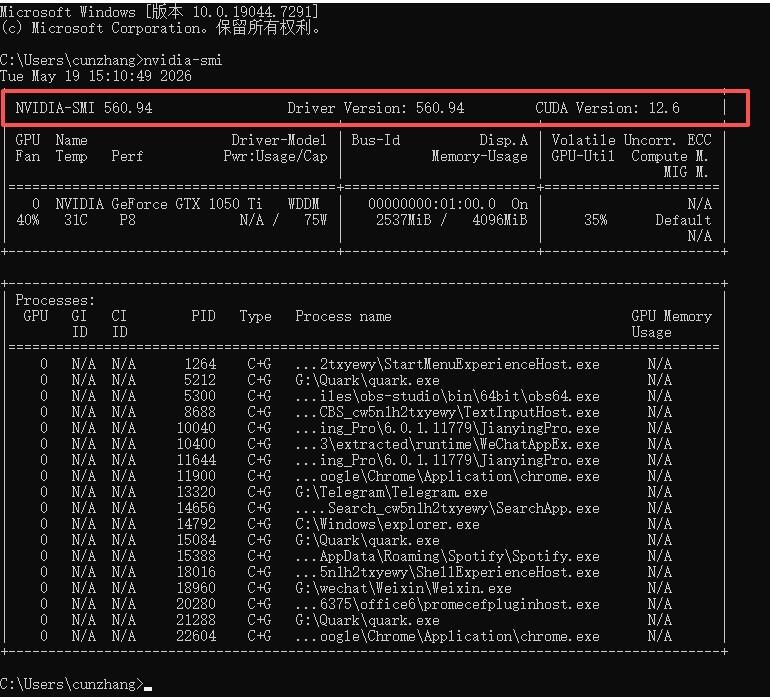
看到的 CUDA 版本号,比如 12.6 就对应 CUDA 12 版本,13 就选 13 版本,对号入座就行。
下载完是个约 200MB 的压缩包,本地解压后你会看到一堆编译好的 exe 文件——这就是你的本地 AI "外壳"了。
🧠 三、准备大模型文件(给外壳装大脑)
外壳有了,还得给它装个"大脑"——也就是模型文件。
🔹 村长实测的模型:Qwen2.5-VL-7B 多模态模型
- HuggingFace:https://huggingface.co/unsloth/Qwen2.5-VL-7B-Instruct-GGUF/tree/main
- 夸克网盘:https://pan.quark.cn/s/1582b15b6eb6
🔹 操作步骤:
- 在解压出来的 Llama.cpp 根目录下,新建一个
model文件夹 - 把下载好的模型文件放进去(多模态模型通常有主模型
.gguf文件和视觉组件mmproj文件,两个都得放)
🔹 其他推荐模型:
- Llama3-8b-DarkIdol(无审查)
- Gemma-4-31b-jang-crack(无审查大模型)
以后想玩任何 GGUF 模型,下载后直接扔进 model 文件夹就行,就是这么简单。
🚀 四、一键启动脚本(双击就跑)
手动敲命令太麻烦,我帮大家写了个一键启动脚本,双击直接跑模型。
🔹 制作步骤:
- 在 Llama.cpp 根目录右键 → 新建文本文档 → 重命名为
start.bat(后缀必须改成 bat) - 右键编辑这个文件,把以下代码粘贴进去(记得核对模型文件名)
@echo off
chcp 65001 >nul
cd /d "%~dp0"
:menu
cls
echo ======================================================
echo 本地大模型一键启动
echo ======================================================
echo.
echo [1] Qwen VL 多模态 (测封面神机)
echo [2] Gemma 31B (无审查大模型)
echo [3] DeepSeek (通用大模型)
echo [4] 退出脚本
echo.
echo ======================================================
set /p choice="请输入数字 (1-4) 并回车: "
if "%choice%"=="1" goto run_qwen
if "%choice%"=="2" goto run_gemma
if "%choice%"=="3" goto run_deepseek
if "%choice%"=="4" exit
goto menu
:run_qwen
cls
if not exist "model\Qwen2.5-VL-7B-Instruct-Q4_K_M.gguf" goto model_missing_qwen
echo 正在启动 Qwen VL 多模态模型...
echo [提示] 自动打开浏览器访问 http://127.0.0.1:8080/
echo.
ping -n 4 127.0.0.1 >nul
start http://127.0.0.1:8080/
llama-server.exe -m "model\Qwen2.5-VL-7B-Instruct-Q4_K_M.gguf" --mmproj "model\mmproj-BF16.gguf" -ngl 12 -t 6 -c 8192
pause
goto menu
:run_gemma
cls
if not exist "model\gemma-4-31b-jang-crack-Q4_K_M.gguf" goto model_missing_gemma
echo 正在启动 Gemma 31B 无审查模型...
echo [提示] 自动打开浏览器访问 http://127.0.0.1:8080/
echo.
ping -n 4 127.0.0.1 >nul
start http://127.0.0.1:8080/
llama-server.exe -m "model\gemma-4-31b-jang-crack-Q4_K_M.gguf" -ngl 4 -t 6 -c 4096
pause
goto menu
:run_deepseek
cls
if not exist "model\deepseek.gguf" goto model_missing_deepseek
echo 正在启动 DeepSeek 模型...
echo [提示] 自动打开浏览器访问 http://127.0.0.1:8080/
echo.
ping -n 4 127.0.0.1 >nul
start http://127.0.0.1:8080/
llama-server.exe -m "model\deepseek.gguf" -ngl 12 -t 6 -c 4096
pause
goto menu
:model_missing_qwen
echo ❌ 错误:未在 [model] 文件夹下找到千问模型文件!
pause
goto menu
:model_missing_gemma
echo 💡 请将 Gemma 模型放入 [model] 文件夹
echo 并右键编辑本脚本,将代码中的文件名改成你的真实文件名。
pause
goto menu
:model_missing_deepseek
echo 💡 请将 DeepSeek 模型放入 [model] 文件夹
echo 并右键编辑本脚本,将代码中的文件名改成你的真实文件名。
pause
goto menu
⚠️ 保存时注意:另存为 → 保存类型选"所有文件" → 编码格式必须选 UTF-8(否则运行时中文会乱码)
保存完,双击 start.bat,输入 1 回车,模型就开始加载了。服务启动后自动打开浏览器访问 http://127.0.0.1:8080/。
🎮 五、实测效果

打开本地网页界面后,UI 非常清爽,模型名称、版本、Token 输出速度全都一目了然。
▍ 多模态图片识别
用的 Qwen2.5-VL 多模态模型,直接扔了一张封面图进去让它分析改进点。实测机器只有 4G 显存,跑 7B 模型稍微吃力,稍微等一会儿后,它还是精准识别出了图片内容,并给出了挺靠谱的修改建议。
💡 显存尴尬的伙伴,建议升级到 8G、12G 或 16G,速度会起飞。
▍ 代码编写能力
让模型写了个 Python 版贪吃蛇游戏。文字对话响应速度明显比图片识别快得多,很快就完整生成了代码。
⚠️ 翻车提醒:第一次测试时,代码写到一半突然断流了。原因是一开始设置的上下文长度(-c 参数)太小。大模型写长代码或分析长文本时,超过上下文限制就会报错。
解决方法:把 -c 参数调大(比如从 4096 调到 8192),重启脚本后贪吃蛇代码一气呵成!
▍ 贪吃蛇完整代码
import turtle
import time
import random
# 初始化屏幕
screen = turtle.Screen()
screen.title("本地AI - 贪吃蛇游戏")
screen.bgcolor("black")
screen.setup(width=600, height=600)
screen.tracer(0)
# 初始化蛇头
snake = turtle.Turtle()
snake.shape("square")
snake.color("white")
snake.penup()
snake.goto(0, 0)
snake.direction = "stop"
# 初始化食物
food = turtle.Turtle()
food.shape("circle")
food.color("red")
food.penup()
food.goto(0, 100)
segments = []
def go_up():
if snake.direction != "down":
snake.direction = "up"
def go_down():
if snake.direction != "up":
snake.direction = "down"
def go_left():
if snake.direction != "right":
snake.direction = "left"
def go_right():
if snake.direction != "left":
snake.direction = "right"
def move():
if snake.direction == "up":
snake.sety(snake.ycor() + 20)
if snake.direction == "down":
snake.sety(snake.ycor() - 20)
if snake.direction == "left":
snake.setx(snake.xcor() - 20)
if snake.direction == "right":
snake.setx(snake.xcor() + 20)
screen.listen()
screen.onkeypress(go_up, "Up")
screen.onkeypress(go_down, "Down")
screen.onkeypress(go_left, "Left")
screen.onkeypress(go_right, "Right")
while True:
screen.update()
# 撞墙检测
if snake.xcor() > 290 or snake.xcor() < -290 or snake.ycor() > 290 or snake.ycor() < -290:
time.sleep(1)
snake.goto(0, 0)
snake.direction = "stop"
for segment in segments:
segment.goto(1000, 1000)
segments.clear()
# 吃食物
if snake.distance(food) < 20:
food.goto(random.randint(-280, 280), random.randint(-280, 280))
new_segment = turtle.Turtle()
new_segment.shape("square")
new_segment.color("grey")
new_segment.penup()
segments.append(new_segment)
# 身体移动
for index in range(len(segments) - 1, 0, -1):
segments[index].goto(segments[index-1].xcor(), segments[index-1].ycor())
if len(segments) > 0:
segments[0].goto(snake.xcor(), snake.ycor())
move()
# 咬到自己检测
for segment in segments:
if segment.distance(snake) < 20:
time.sleep(1)
snake.goto(0, 0)
snake.direction = "stop"
for seg in segments:
seg.goto(1000, 1000)
segments.clear()
time.sleep(0.1)
复制代码,本地新建 Python 文件(记事本粘贴,另存为选"所有文件"和 UTF-8 编码),用 PowerShell 运行后贪吃蛇窗口直接弹出,键盘操控完美。本地大模型这波表现,我给 90 分!
🛠️ 六、启动参数说明
脚本里的几个关键参数,搞懂了才能调优:
| 参数 | 说明 | 建议值 |
|---|---|---|
-m |
模型文件路径 | 你的 .gguf 文件名 |
--mmproj |
多模态视觉组件 | 多模态模型必填 |
-ngl |
GPU 层数 | 根据显存调整(4G→4层,8G→12层) |
-t |
CPU 线程数 | 一般设为 6 |
-c |
上下文长度 | 4096起步,写代码建议 8192+ |
💡 调参建议:显存不够就减少
-ngl,上下文不够就增大-c,这两招最实用。
👥 七、适合哪些人?
- ✅ 隐私党:不想把数据交给云端,本地跑模型数据不出门
- ✅ 折腾党:手里有显卡想玩 AI,又不想折腾环境配置
- ✅ 开发者:需要本地测试模型效果、调试代码
- ✅ 小白用户:Llama.cpp 这次把门槛降到最低,解压就能用
💬 八、常见问题
Q1:4G 显存能跑什么模型? 建议跑 7B 参数的量化版本。4G 确实吃力但能跑。追求速度的话选 3B 或 1.5B 的小模型,或者升级到 8G 以上显存。
Q2:纯 CPU 电脑能跑吗? 可以。Llama.cpp 对 CPU 推理优化很好,选常规 x64 版本就行。但速度比 GPU 慢不少,建议选小参数模型或量化程度更高的版本(Q4、Q3)。
Q3:脚本运行后网页打不开?
检查三点:① 命令行窗口没有报错 ② 浏览器访问的是 http://127.0.0.1:8080/ ③ 防火墙没有拦截
Q4:多模态不识别图片?
确认两个文件都放对了:主模型 .gguf 文件和视觉组件 mmproj 文件都得在 model 文件夹中,启动脚本里要正确指定路径。
📌 总结
本地 AI 的门槛已经被 Llama.cpp 彻底踩碎了:
- 🔧 免配置:下载解压即用,不再折腾环境
- 🎮 全显卡支持:N 卡、A 卡、Intel、纯 CPU 都能跑
- ⚡ 一键脚本:双击启动,自动搭建 Web 界面
- 🧠 模型丰富:Qwen、DeepSeek、Gemma 等主流 GGUF 模型全支持
感兴趣赶紧去下载折腾吧!有问题评论区交流。
📚 相关文章推荐
你可能还想看:
📢 关注「Geek 运维」
了解更多最新 Geek 技术分享!

长按识别图中二维码,关注「GeeK 运维」公众号,获取:
- 最新 AI 技术资讯
- 实用技术教程和工具
- OpenClaw/Skills 使用指南
- 运维开发最佳实践
- 第一手技术资源分享
评论区