


本地 AI 模型部署实战:vLLM 让 OpenClaw 推理性能飙升 10 倍!
想要 OpenClaw 执行自动化任务时丝滑流畅?想要避免上下文超限的尴尬?本地部署开源模型可能是你的最佳选择!
为什么要部署本地模型?
在使用 OpenClaw 执行自动化任务的过程中,你是否遇到过这些问题:
- 任务执行到一半突然卡顿
- 频繁触发上下文长度限制
- 云端 API 调用成本居高不下
如果你希望获得更流畅、更稳定的使用体验,同时降低使用成本,那么本地部署开源大模型绝对值得尝试!
对于 OpenClaw 这类自动化工具来说,选择模型时有几个关键指标:
- 推理能力:能否准确理解任务意图
- 语言理解:对中文的支持是否友好
- 工具调用能力:能否稳定调用各种工具完成操作(这是最重要的!)

框架选型:为什么放弃 Ollama 选择 vLLM?
初次接触本地模型部署的朋友,大概率会听说 Ollama。没错,Ollama 确实有它的优势:
- 安装简单,几乎零配置
- 一键部署,新手友好
- 社区活跃,模型丰富
但是! 在 OpenClaw 这种需要频繁调用工具的自动化场景下,Ollama 的表现并不理想:
❌ 推理速度偏慢
❌ 上下文容易被耗尽
❌ 多任务连续运行时频繁出错
经过实际测试和对比,我们发现:
| 场景 | 推荐框架 |
|---|---|
| 远程集群 / 多 Agent 协作 | SGLang |
| 单卡本地部署 | vLLM ⭐ |
vLLM 凭借其优秀的推理性能和稳定的工具调用能力,成为单机部署 OpenClaw 的首选方案。
手把手部署教程
🛠️ 准备工作
开始前,建议先安装 Windows Terminal,这款现代化的终端工具支持 PowerShell、WSL 等多种 Shell,切换系统更方便。
第一步:安装 WSL2 子系统
以管理员身份打开 PowerShell,执行:
wsl --install
等待安装完成后重启电脑,然后安装 Ubuntu 发行版:
wsl --install -d Ubuntu
验证安装版本:
wsl --version
确保输出显示 WSL 版本:2
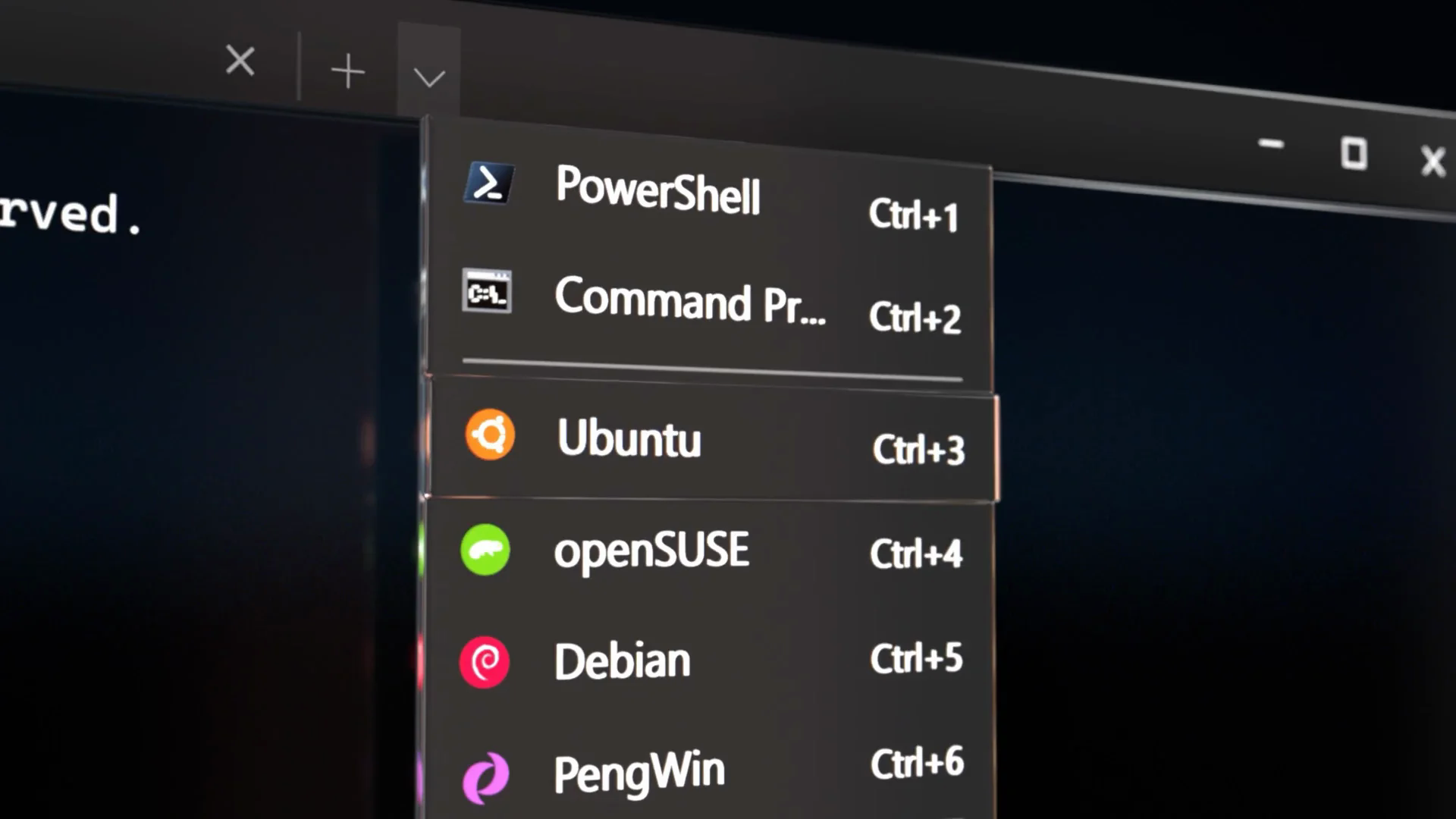
第二步:配置 CUDA GPU 支持
首先确认 Windows 已正确安装 NVIDIA 显卡驱动:
nvidia-smi
然后在 WSL Ubuntu 环境中再次执行:
nvidia-smi
如果能看到显卡信息,说明 GPU 直通配置成功!
第三步:搭建 Python 运行环境
更新系统软件包:
sudo apt update && sudo apt upgrade -y
安装 Python 及必要组件:
sudo apt install python3-pip python3-venv -y
创建独立的虚拟环境(推荐做法):
cd ~
python3 -m venv vllm-env
source vllm-env/bin/activate
第四步:安装 vLLM 推理框架
升级 pip 到最新版:
pip install --upgrade pip
安装 vLLM:
pip install vllm
验证安装:
python -c "import vllm; print('vLLM 安装成功!')"
第五步:选择合适的模型
我们推荐使用:Qwen2.5-14B-Instruct-AWQ
选择理由:
- ✅ 中文理解和表达能力出色
- ✅ Agent 任务处理能力强
- ✅ 工具调用支持完善
- ✅ AWQ 量化后显存占用更低
💡 显存提醒
本教程基于 24GB 显存显卡(RTX 4090)。如果你的显存较小: - 16GB:可选择 Qwen2.5-7B-Instruct-AWQ - 8GB:可选择 Qwen2.5-4B 或更小模型
vLLM 会在首次启动时自动下载模型文件。
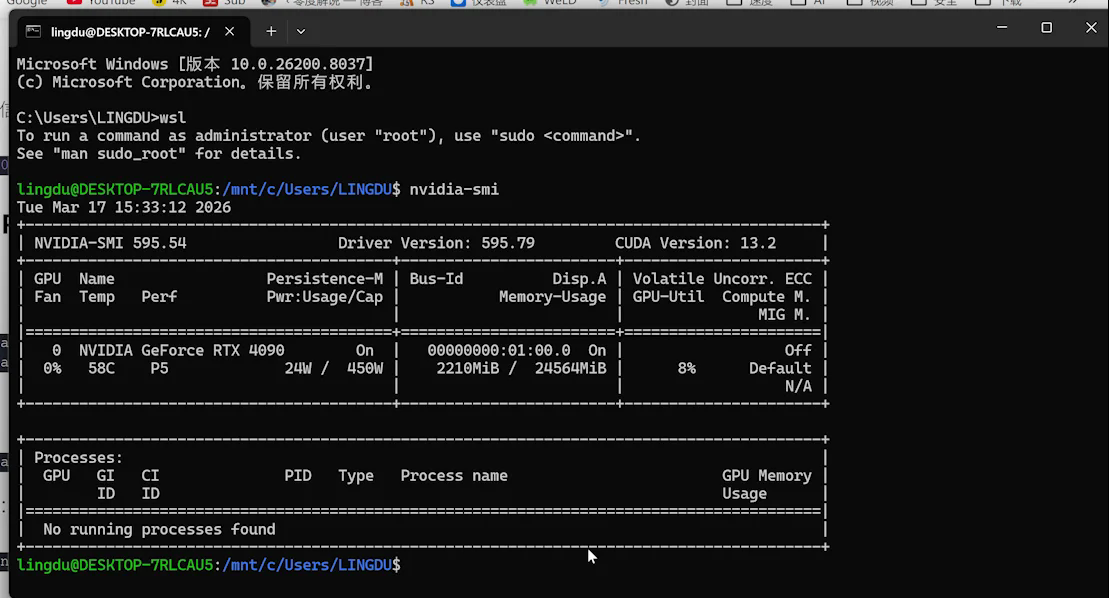
第六步:启动 vLLM 服务
执行以下命令启动 API 服务:
python -m vllm.entrypoints.openai.api_server \
--model Qwen/Qwen2.5-14B-Instruct-AWQ \
--quantization awq_marlin \
--gpu-memory-utilization 0.9 \
--max-model-len 32768 \
--enable-auto-tool-choice \
--tool-call-parser hermes
看到类似以下输出说明服务启动成功:
第七步:验证模型服务
打开 Windows PowerShell,执行测试请求:
curl http://127.0.0.1:8000/v1/models
如果返回模型信息(包含 Qwen/Qwen2.5-14B-Instruct-AWQ),说明服务运行正常。
第八步:安装 OpenClaw
在 WSL 环境中执行:
安装 Node.js 运行时:
curl -fsSL https://deb.nodesource.com/setup_22.x | sudo -E bash -
sudo apt install -y nodejs
安装 OpenClaw:
sudo npm install -g openclaw@latest
第九步:配置 OpenClaw 连接本地模型
运行配置向导:
openclaw onboard
添加自定义模型提供商:
| 配置项 | 值 |
|---|---|
| 模型提供商 | 自定义 |
| Base URL | http://127.0.0.1:8000/v1 |
| API Key | 任意填写(如 123456) |
| 模型名称 | Qwen2.5-14B-Instruct-AWQ |
保存配置,完成!
🚀 性能优化技巧
优化 OpenClaw 参数
在 OpenClaw 配置中调整以下参数,可避免卡顿:
Context length: 6000-8000
Temperature: 0.7
Max tokens: 2048
优化 vLLM 启动参数
针对 RTX 4090 的优化配置(请根据自己显卡调整):
python -m vllm.entrypoints.openai.api_server \
--model Qwen/Qwen2.5-14B-Instruct-AWQ \
--quantization awq_marlin \
--gpu-memory-utilization 0.9 \
--max-model-len 32768 \
--enable-auto-tool-choice \
--tool-call-parser hermes
优化效果:
- ✅ Prefix Cache 加速 Prompt 处理
- ✅ GPU 利用率显著提升
- ✅ 并发请求响应更快
解决长对话卡顿问题
在 OpenClaw 的 System Prompt 中添加:
When the conversation becomes long,
summarize previous messages into a short memory.
Keep the memory under 200 tokens.
这样可以将 8000 token 的上下文压缩到 200 token,保持推理速度不下降。
📊 性能测试结果
在 RTX 4090(24GB 显存)上的实测数据:
| 性能指标 | 实测数值 |
|---|---|
| Token 生成速度 | 90-130 token/s |
| 首 Token 延迟 | 0.4-0.8 秒 |
| 最大上下文 | 32K tokens(建议 8K-16K) |
| 显存占用 | 10-12GB |
这个性能表现,用来运行 OpenClaw 已经完全够用!
💡 总结与建议
通过 vLLM 部署本地模型,你将获得:
- 极速推理:90-130 token/s 的生成速度
- 超低延迟:首 Token 仅需 0.4-0.8 秒
- 完美兼容:工具调用能力稳定可靠
- 经济高效:14B 模型仅需 10-12GB 显存
如果你正在使用或计划使用 OpenClaw,这套本地部署方案绝对值得一试!
📚 相关文章推荐
你可能还想看:
- GitHub开源工具推荐:本周最火的5个效率神器,第3个绝了
- 还在纠结选哪个?Claude 4、GPT-5、Gemini 2.5深度对比,2025年最适合你的大模型
- Linux服务器运维完全手册:性能调优+故障排查,运维工程师必备
- Linux运维技巧:Linux 性能调优完全手册
- Openclaw配置Glm模型全攻略:官方免费API Key部署教程
📢 关注「Geek 运维」
获取更多 AI 技术干货和实战教程!

长按识别图中二维码,关注「Geek 运维」公众号,你将获得:
- 🔥 最新 AI 技术资讯和趋势解读
- 🛠️ 实用技术教程和效率工具
- 📖 OpenClaw/Skills 深度使用指南
- 💻 运维开发最佳实践分享
如果本文对你有帮助,欢迎转发分享给更多朋友! 👍
评论区